Providers: The Network’s Computational Backbone
Overview
At the core of the Spheron network lies the Provider Node, a pivotal entity responsible for contributing both CPU and GPU resources to a communal pool. This section explores the architecture, operational mechanics, and incentive framework designed to sustain high network integrity and reliability. Through a combination of staking, rewards, and a sophisticated deployment orchestration system based on Kubernetes, Provider Nodes are incentivized to offer their computational resources, thereby ensuring the network’s robustness and scalability.
Architectural Overview
Provider Nodes constitute the network’s backbone, offering essential CPU and GPU resources essential for powering a wide array of applications. Leveraging Kubernetes, these nodes facilitate the orchestration of deployments, enhancing the network’s ability to scale dynamically in response to varying computational demands. This orchestration capability not only simplifies deployment management but also significantly improves the network’s overall efficiency and responsiveness.
Provider Registration
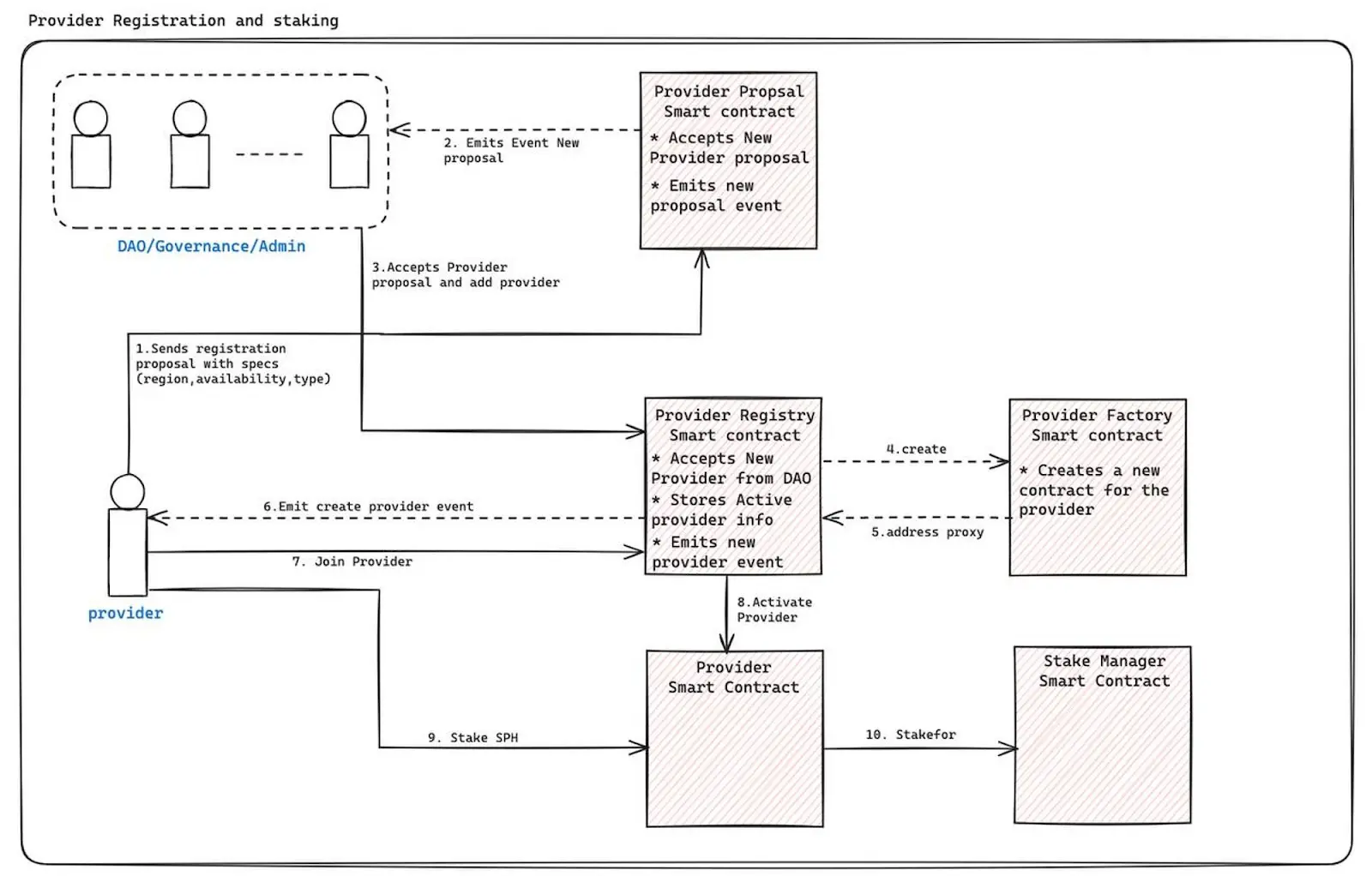
For providers to join the network, they must undergo a comprehensive verification process. This procedure is designed to ensure that only legitimate providers with adequate compute resources and no malicious intent are integrated into the network. The verification process involves several steps and is overseen by the decentralized autonomous organization (DAO) or governance body through a voting system.
- Provider Registration Proposal: Providers interested in joining the network must first submit a registration proposal. This proposal includes detailed specifications about the provider’s resources, such as region, compute capacity, tier, and type of compute.
- Governance Review: The governance body reviews the proposal. Upon approval, the provider’s details are registered in our Provider Registry smart contract. This registration triggers the creation of a new smart contract specific to the provider, updating the proxy address in the registry contract.
- Staking Requirement: Following registration, providers are required to stake $SPON tokens. This stake activates the provider’s bidding engine, allowing them to start submitting bids for new deployments.
NOTE: Initially, to lower barriers to entry and accelerate network growth, provider registration proposals will be automatically approved. However, once the network reaches a certain level of maturity, we plan to introduce a curation process by submitting a governance proposal to disable the automatic approval mechanism.
Proof of Compute
To protect our network against fraudulent activities and ensure that providers genuinely contribute the advertised compute and GPU resources, we propose implementing several proof mechanisms:
- Random Verification: Providers may be required to perform proofs of their compute or GPU capacity, uptime, and regional location at random intervals.
- Challenge Mechanism: Users have the opportunity to challenge providers to verify the authenticity of the provided resources.
NOTE: We are currently refining the full architecture of these verification mechanisms, with further details to be published soon.
This structured approach to provider onboarding (and verification not only enhances the security and integrity of the network but also ensures that all participants are contributing positively to the ecosystem’s overall functionality and trustworthiness.
Provider Attributes
In our decentralized compute network, providers can specify various attributes that assist the Matchmaker in selecting an appropriate provider based on user requests. During the initiation phase, providers are encouraged to detail these attributes to optimize the matchmaking process. Here is a systematic breakdown of the different types of attributes that providers can declare:
Compute Tier
Providers categorize their compute servers into distinct tiers based on CPU performance scores, enabling a precise match with the computational demands of user projects:
- High Performance Compute (HPC) Tier: These are robust servers equipped with modern next-generation EPYC processors, characterized by CPU scores exceeding 50,000.
- General Purpose Tier: This tier includes older generation servers with CPU scores below 50,000, widely available and capable of handling a variety of general computing tasks.
- Basic Tier: Comprising servers with no more than 48 threads and CPU scores below 20,000, these units offer essential computing power at a lower cost.
- Storage Tiers: Focused on data storage capabilities, this category is subdivided into:
- SSD Storage Tier: Servers predominantly equipped with Solid State Drives.
- NVME Storage Tier: Servers outfitted with Non-Volatile Memory Express drives, offering faster data transfer rates.
For a comprehensive overview of the CPU tiers and their specifications, please refer to the CPU Tiering section in our user guide. This resource provides detailed information on each tier’s performance characteristics and typical use cases, helping users make informed decisions when selecting Provider Nodes for their CPU-intensive tasks.
GPU Tiers
GPU providers specify the performance tier of their hardware, which influences their suitability for different computational tasks:
- Entry Tier: Suitable for basic model inferencing, these GPUs are priced below approximately $1,000 and offer modest performance.
- Low Tier: Priced under approximately $2,000, these units are adequate for less demanding machine learning tasks and inferencing.
- Medium Tier: Commonly used in commercial applications for distributed training and model inferencing, with a price point under $5,000.
- High Tier: These premium GPUs, priced above $7,500, are scarce and predominantly utilized for training large language models (LLMs) and other intensive tasks.
- Ultra High Tier: These premium GPUs, priced above $15,000, are high capital intensive and predominantly utilized for training large language models (LLMs) and other intensive tasks.
For a comprehensive overview of the GPU tiers and their specifications, please refer to the GPU Tiering section in our user guide. This resource provides detailed information on each tier’s performance characteristics and typical use cases, helping users make informed decisions when selecting Provider Nodes for their GPU-intensive tasks.
Connectivity Tier
Providers can also declare their connectivity capabilities, which are crucial for data-intensive tasks:
- Low Speed: Download speeds less than 100 Mbps and upload speeds less than 75 Mbps.
- Medium Speed: Download speeds less than 500 Mbps and upload speeds less than 400 Mbps.
- High Speed: Download speeds less than 1 Gbps and upload speeds less than 800 Mbps.
- Ultra High Speed: Download speeds exceeding 5 Gbps and upload speeds exceeding 5 Gbps.
NOTE: All these tiers will have different multiplier for the liveness reward provided by the protocol, an extensive details will be provided later during our testnet phase.
Incentive and Staking Mechanism
Provider Nodes are mandated to stake $SPON tokens to participate in the network actively. This staking mechanism fulfills several critical roles: it secures a vested interest in the network’s prosperity, establishes a method for penalizing misconduct, and synchronizes providers objectives with the network’s overarching goals. Acts of malfeasance such as prolonged downtime, delays in system upgrades, or misuse of user deployments incur penalties, including the slashing of stakes. This robust accountability framework is instrumental in bolstering network security and maintaining participant trust.
Reward System for Provider Nodes
Provider Nodes receive compensation based on the utilization of their computational resources. This reward structure is meticulously designed to motivate the ongoing provision of resources while ensuring that contributions are equitably remunerated. Additionally, in periods of low utilization or idle period, the foundation provides liveness incentives to ensure that providers remain active within the network, thereby preventing potential exits due to insufficient returns on investment (ROI) or inability to cover operational expenses (OpEx).
Delegation of $SPON Tokens and Rewards
The system also enables the delegation of $SPON tokens to Provider Nodes by token holders aiming to strengthen network security. This mechanism increases a node’s likelihood of being selected for deployments, enhancing potential earnings. Providers need to provide a commission on the rewards earned by the liveness rewards given by the foundation, which will be allocated to the stakers to provide delegation on their node.
The Annual Percentage Rate (APR) for stakers is dynamic, influenced by factors such as the provider’s liveness rewards during a given epoch, and the network’s inflation rate. This comprehensive incentive and staking mechanism ensures that Provider Nodes are not only motivated to maintain high standards of operation but are also financially supported to sustain participation in the network, thereby aligning individual success with the network’s overall health and longevity.
Slashing Mechanism
Providers are subject to penalties for any misconduct within the network, such as user data misuse or spoofing, as identified by the Spheron Team or the broader ecosystem. In such instances, the provider’s $SPON collateral—which includes both staked and delegated funds—along with any accrued rewards, will be slashed. This measure is intended to provide restitution for any data breaches or other damages inflicted upon consumers.
Additionally, providers face penalties for downtime during active leases. The value of the liveness reward corresponding to the duration of the downtime is deducted from the provider’s $SPON collateral. In scenarios where there are no active leases, only the liveness rewards are slashed, sparing the main collateral. However, providers can enter Maintenance Mode during scheduled maintenance or upgrades to prevent collateral slashing during these periods.
To ensure stability within the network and discourage intermittent connectivity, a cooldown period of 3 hours is imposed on earning Availability Rewards whenever a node is terminated or paused and then reconnected. This policy aims to promote consistent service availability and prevent nodes from exploiting the reward system through frequent disconnects and reconnects.
Operational Dynamics
The operational life cycle of a Provider Node encompasses several key stages:
- Registration and Bidding: Initially, Provider Nodes register their compute specs, region, tier, etc on the Provider Registry. Utilizing a bid engine, these nodes can compete for deployments by submitting bids to the Order contract against each deployment that reflect their capacity to deploy the order and pricing model for the compute specs. Successful bids lead to user choosing the provider to deploy their workloads, with all pertinent details shared on-chain, marking the beginning of payment settlement based on the pricing set by the provider.
- Deployment and Management: Provider Nodes are responsible for the continuous management of deployments, including the initiation
(CREATE_LEASE), update(UPDATE_LEASE), and termination(CLOSE_LEASE)of services. Each action is meticulously recorded on the blockchain, ensuring transparency and traceability.
The Provider Node is instrumental in achieving the decentralized compute network’s vision of an accessible, scalable, and secure computational resource ecosystem. Through a balanced approach combining technological sophistication with an incentivized participation model, Provider Nodes ensures the network remains adaptive and resilient. As the network evolves, the continuous refinement of Provider Node operations and governance mechanisms will be paramount in sustaining the growth and vitality of the decentralized computing landscape.